
Automatic Code Generation of Complex Business Rules
Dr. Paul Dorsey
Dulcian, Inc.
Overview
Implementing business rules within a database system is a challenging task. Traditionally, this has been handled by placing a small subset of the business rules into the database using a variety of techniques:
We have no illusion that all data-related business rules are easily supported within a data model. For example, there is no easy way to prevent loops in recursive structures when you are modeling hierarchical information. There is a whole other class of business rules that we traditionally handle through application logic. There has been much discussion of business rules in the last few years, but relatively little discussion of actual implementations of these rules. There are several underlying principles to the approach we used in implementing business rules:
Business rules, components of these rules, connections between these rules, and their impact on other entities in the data model are all "things of interest" just as Employees or Departments. You can use the same data modeling skills to model these as any other item of interest.
If you are accustomed to the idea of generic modeling, including storing column information as data, overloading entities, etc., the style of modeling described here will be easier to understand. Modeling business rules involves the modeling of abstractions.
Once the business rules are stored in the database, you can drive programs using data from the tables. However, if you use this method, you may end up with terrible performance due to many database accesses. You may also need to utilize DBMS sequel frequently in your program logic. The ability of PL/SQL to support this type of data driver program is somewhat limited since there are no C++-style pointers and only limited indirect variable referencing through COPY and NAME_IN commands. Therefore, one of the possible strategies is to have all data in the system and write a program to take data and build PL/SQL packages (limited code generator).
Supporting Database Business Rules
At one client, the Lancaster County Tax Collection Bureau (LCTCB), we created a system (RADS) requiring a complex business rules engine. The RADS system involves management and processing of documents associated with tax collection. There is a complex workflow associated with these documents involving data validation, corrections of errors in the documents, and processing and distribution of funds.
There are aspects of RADS that make it particularly appropriate for using object-oriented structures. First, there are a number of different types of documents, such as individual and employer tax returns. Second, the types of operations performed on all of the documents are very similar. We must count on being in an environment where we support new documents--that is, monthly rather than quarterly employer reports or entirely different documents because of tax reform. If we built this system in a traditional fashion, any of these modifications would require significant restructuring of the system.
The automated support of business rules has been one of the hottest topics in the Oracle community for the last few years. The industry has tried using general business rule grammars (with no success), extending the Oracle Designer repository (with some success), and writing limited business rule generators (quite successfully).
Until recently, we were of the opinion that the quest for a general business rule generator was probably futile. There was no way that we would be able to get a reasonable set of business rules specified and generated. Business rules are too complex, and always require custom coding. After all, we already have a way of describing complex business rules; we call it PL/SQL.
At the same time, we have been building several limited business rule engines with great success. Each of these engines was more robust than the last, but none of them seemed to come anywhere close to something that we would want to use for trigger generation.
Then, as part of the RADS project, we designed yet another limited engine to support validation of tax returns (to make sure that Line1 + Line2 = Line3 on your tax return). We built the code to parse rules and generate procedures. While writing up the system documentation for the engine design, it occurred to us that just as we could validate data in a document, we could validate data in a database.
We will not assert that the quest for the ultimate business rule engine has been achieved. We are still only able to generate relatively simple business rules, though we can store and maintain the most complex rules in the system. We still don’t think we can build the perfect business rule code generator, but I think we can get pretty close.
In the following sections, we will discuss the design of the Business Rule Integrated Database Generator Engine (BRIG). First, I will discuss the types of rules that we wanted to support along with the other system requirements; then, the design will be described.
Rule Requirements
There are basically four different kinds of business rules that are commonly supported in systems that we design:
Other System Requirements
There were several requirements for the system:
The Design of the Business Rules Information Generator (BRIG)
The first debate occurred about whether or not to store our rules in a repository outside of Oracle Designer. By storing the rules in a separate repository, there were some trade-offs. On the positive side, rules could be stored in a complex structure not easily supported through user extensions. (We considered extending the repository to store the rules, but we wanted to have the system in production for a while before we made that decision.) We were interested in writing very complex code against repository extensions for a first version. On the negative side, we would be storing many of our business rules outside of the Oracle Designer Repository. This would put our business rules in two places.
We decided to build a separate rules repository. The rationale was that our projects are not built to simply support a set of rules; rather, they are built to support a class of rules. That is to say, the flexible business rules are part of the implementation, not the design.
We made several key design decisions:
Our solution for the system involved building a small repository to hold our rules with some simple forms to support rule maintenance.
Rather than enforce the rules through lookups into the repository, we elected to use the repository to generate database triggers.
We noticed that if we supported rules that used custom functions that we could support arbitrarily complex rules through hand-coding some functions. Eventually, a function generator could be added to support generation of types of complex functions.
We decided to build rules in two steps. First we would build elementary conditions, such as START_DATE < END_DATE, and then combine them using Boolean operators. Then we could simply refer to "RULE1 and RULE2".
The structure to hold the rules was rather complex, designed for non-intuitive data entry. To simplify this for users, we allowed them to enter the rules using normal programming syntax. We then wrote a parser to place their rules into the repository. (In practice, users wrote their rules in English and junior programmers entered the actual rules.)
We made an addition to the standard Boolean operators to support easier entry of rules. Specifically, we added an IF THEN ELSE structure to support conditional constraints (described above). "RULE1 => RULE2 else RULE3" would be interpreted as "(RULE1 and RULE2) or (not RULE1 and RULE3)". Similarly, "RULE1 => RULE2" would be interpreted as "(RULE1 and RULE2) or (not RULE1)".
We noted that rules fell into four categories for implementation:
We had to support each type of constraint differently. Check constraints were limited to lists of values and ranges. Conditional triggers supported most complex rules. Redundant columns were supported with triggers (avoiding mutating tables was a significant problem). Recursive rules required a little different thinking.
Rule Storage
It is probably not obvious to the reader how rules are supported in a database structure. Note that we are storing rules using a parse tree. For example, the rule (Col1 + Col2)/2 < Col3 is represented in Figure 1.
Figure 1: Sample Rule Parse Tree
Similarly, compound rules are stored in a separate (but similar) structure. The difference is that instead of combining parameters through operators, we are combining rules through Boolean operators. For example, the compound rule "(RULE1 and RULE2) or (not RULE3)" would be represented as shown in Figure 2.
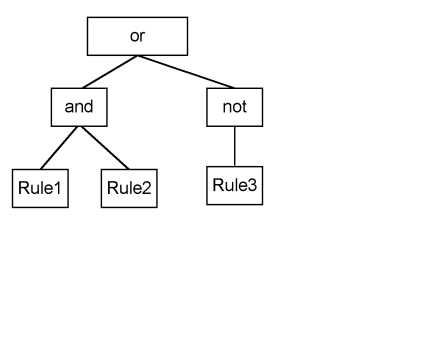
Figure 2: Sample Compound Rule
Note that for rules, each element is either a function or a column. For compound rules, each element is either a Boolean operator or a rule.
If you are familiar with generic modeling techniques, the data model for BRIG is relatively straightforward. Triggers are related to tables and columns. Both simple data rules and compound rules are simple master detail and recursive structures as shown in Figure 3.
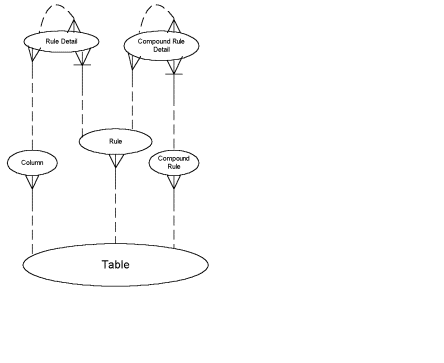
Figure 3: Core of BRIG™ Data Model
With a structure genericized to this extent, unlike many database applications, the core of the system is not in the data model. Once we thought through the structure of a business rule, the storing of the business rules was not very difficult. The question that remained was what to do with the business rules once they were stored. Two alternatives were considered:
Our decision was to use this engine to create large text files that would either create triggers on tables or alter the existing triggers on tables. We ended up building something that would write text files, which, when executed within SQL*Plus would create SQL packages. When these SQL packages, in turn, were executed, they would create or alter the appropriate triggers. This strategy greatly simplified the problem of handling the stored business rules. My company, Dulcian, Inc., already created DataMIG™, a PL/SQL code generator that writes text files, which, when executed, generate PL/SQL packages that migrate data when executed. Therefore, the problem of automatic code generation was one we had already worked on for a number of years.
In order to support the alteration of existing triggers, we needed to identify portions of triggers that BRIG had created versus portions coming from other sources. To accomplish this, we used the same method as Oracle Designer, which is to place easily identifiable comments around trigger code that BRIG adds to triggers. Specifically, all BRIG triggers start with "- - -BRIG- - - -" and end with "- - - -END BRIG- - - -." This allowed us to detect whether there was any BRIG code in an existing trigger so that we could replace it or add to it as appropriate.
Testing the depth of BRIG™
The first test we set for BRIG™ was to see if it could support the complex data-related business rules for BRIG’s own data structure. Although it is only comprised of a few tables, the BRIG™ repository is quite complex. The following business rules could not be supported through referential integrity and check constraints:
Such rules can be entered into the system and generated. However, attempting to generate these rules points out the limitations in the rule engine. Each of these rules requires that we write a specific function to look up the correct data to make sure that model consistency is enforced. Some common functions such as summing up the details and storing them in a master (such as for a purchase order) can be classified and generated, but most other complex rules (such as ALL the complex rules for this system) still need custom coding. In applying the BRIG to a standard OLTP, the results are somewhat better. However, most complex rules require the writing of a custom function. BRIG works perfectly for almost all simple rules and helps in the maintenance of complex rules (though they still require some custom coding).
Our opinion hasn’t changed that a generalized business rule engine that would support all rules can never be built. If someone can build a grammar that will allow generation of rules such as the ones required by the BRIG data structure itself, then we will gladly retire BRIG to the scrap heap. Until then, BRIG stands as a pretty good attempt at a generalized rule engine that generates 100 percent of the code for simple rules and helps to maintain complex rules.
Conclusion
BRIG has had a profound impact on our design process. Now, business requirements are placed directly in the repository late in the Analysis phase. This tends to blur the line between analysis and development. As soon as rules are placed in the repository, they can be generated. No additional coding time is required.
The system has made us much more secure in our design process. If we decide that rules are too restrictive, they can be regenerated very quickly. Using BRIG, we can support a much larger percentage of our business rules without custom coding.
About the Author
Dr. Paul Dorsey is the President of Dulcian, Inc., an Oracle consulting firm that specializes in data warehousing, systems development and products that support the Oracle environment. Paul is co-author with Peter Koletzke of Oracle Press’ Oracle Designer Handbook and with Joseph Hudicka of Oracle Press’ Oracle8 Design Using UML Object Modeling. Paul is an Associate Editor of SELECT Magazine. Paul is also collaborating on a book about Oracle Developer. He is President of the NY Oracle Users’ Group and very active in the Oracle user community. Paul has won best presentation for both ECO and IOUW and was a finalist for best presentation at ODTUG. He and Peter Koletzke shared the Pinnacle Publishing Technical Achievement Award at ECO for their work on an Oracle Forms template. Paul can be contacted at pdorsey@dulcian.com or through Dulcian’s Website at http://www.dulcian.com/.
©1999 Dulcian, Inc.